
この記事は、当社の ウェビナーシリーズのハイライトを振り返るブログシリーズの一部です。このウェビナーシリーズでは、業界の専門家たちが、公益事業会社における内部ネットワークセキュリティ監視(INSM)プログラムの構築から得た知見や現場での教訓を共有しています。
第5回では、CIP-015の核心となる要件、すなわち「異常なネットワーク活動の検知」について取り上げました。今回は、Nozomi Networks 、サイバーセキュリティ戦略担当ディレクターのクリス・グローブ氏をゲストに迎えました。私は公益事業およびNERC CIPのバックグラウンドからこのテーマに取り組んでいます。 私はNERC CIPプログラムを運営し、長年にわたりこのコミュニティで活動してきました。一方、クリスは検知エンジニアリングの観点からこのテーマに取り組んでいます。コンプライアンスに精通した人物と、検知の現場に身を置く人物というこの対比こそが、こうした対話を価値あるものにしており、対話を重ねるたびに私は新たな発見を得ています。
「異常(Anomalous)」:定義のない言葉
NERC CIP-015-1 の要件 R1 では、事業体に対して 2 つのことを求めています。すなわち、異常なネットワーク活動を検出するための 1 つ以上の手法を導入すること(第 1.2 項)と、その活動を評価して今後の対応を決定するための 1 つ以上の手法を用いること(第 1.3 項)です。この要件のすべては、「異常(anomalous)」という 1 つの言葉にかかっていますが、ここで問題となるのは、これが NERC の用語集に載っていない用語であるという点です。
起草チームの技術的根拠では、「異常(anomalous)」を「予期せぬ、望ましくない、通常とは異なる、あるいは原因不明のネットワークトラフィック」と説明しています。メリアム・ウェブスター辞典では、「通常、正常、または予想される状態と一致しない、あるいはそれから逸脱している。不調和や矛盾を特徴とする」と定義されています。多くの実務家は、悪意のある活動、不正なトラフィック、あるいはベースラインからの逸脱など、まったく異なる意味をこの言葉に当てはめています。 ここでは言葉の選び方が極めて重要だ。なぜなら、何かが明確に定義されていない場合、次の2つの事態が生じるからである:
- 自分で定義する必要があります
- それをどのように定義するかによって、プログラムのその後のすべての動作が決まります
まず前もって言っておきますが、「異常」と「悪意」を同一視するのは賢明ではありません。なぜでしょうか? 検出された時点では、それが悪意のあるものかどうかを判断できることはめったにないからです。それが悪意のあるものかどうかは、評価と根本原因の分析を経て初めて判明するものです。
異常検知において、文脈こそがすべてである
家庭用火災報知器について考えてみてください。それが鳴ったとき、それは「異常」なのでしょうか?午前3時にその音を聞いた人にとっては、間違いなく「異常」でしょう。しかし、そのシステムを設計したエンジニアにとってはどうでしょうか?いいえ、煙を感知したとき、それはまさに設計通りに機能しているに過ぎません。では、金曜日の夜、誰かがコンロで魚を焦がしているときはどうでしょうか?場合によっては、そうかもしれません。 文脈がすべてです。文脈がなければ、異常とは単にパターンによって記述された事象に過ぎず、ある人にとっての異常が、別の人にとっては日常業務そのものになるのです。
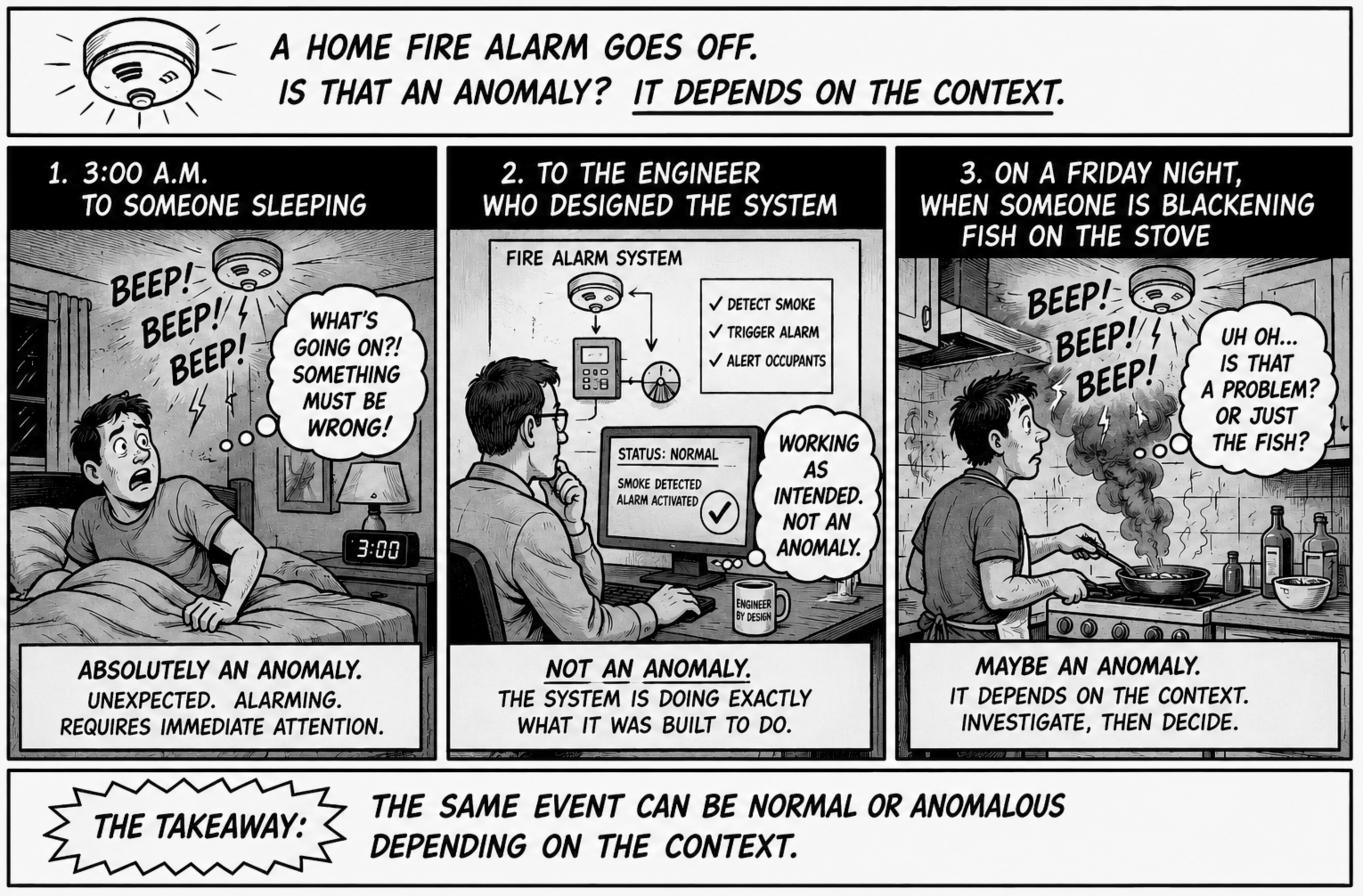
OT常に起こっていることです。タービンの振動センサーは、通常時はゼロの状態で静かに動作していますが、ある時点で「1」に切り替わります。制御システムにとっては、これは想定内の挙動であり、物理的な問題を早期に検知することにつながります。しかし、基準値からの逸脱という観点から見れば、これは100%異常です。なぜなら、正常な状態はゼロであったのに、現在はそうではないからです。これを異常として捕捉するかどうかは、組織の方針次第です。
「既知」と「未知」、そしてその両方が必要な理由
どのような制御システムネットワークにおいても、私たちが把握していることと、把握していないことがあります。エンジニアのステーション、通常のログイン情報、IEDへのコマンド送信に使用されるプロトコルなどは把握しているかもしれません。しかし、より厄介なのは「未知の要素」です。もし誰かがそのステーションからコマンドを発行した場合、それが悪意のあるものかどうかを判断できるでしょうか? 可視性が確保されていない場合、送信されたコマンド自体を検知できず、ステータスの変化だけが確認されるだけかもしれません。 難しいのは「未知の未知」、つまり「自分が知らないことさえ知らない」という状況です。OT において言えば、許可されたプロトコルを使用しているものの、通常とは異なる方向へ向かうパケットや、HMIがIEDから読み取るのではなく、突然IEDに書き込みを行うようなケースがこれに該当します。
署名だけではINSMの趣旨を満たすことはできませんが、必ずしもプロセスレベルの詳細まで網羅する必要もありません。これはリスクに基づいた判断であり、組織やチームの実情に応じて、自組織のプログラム内でその正当性を説明すればよいのです。
シグネチャは、既知の脅威(既知のマルウェア、既知の攻撃者の活動、既知の侵害の兆候(IOC))を検知するための手段です。シグネチャは価値が高く、適切に作成されていればノイズも少なくなります。しかし、シグネチャは常に遅れをとります。これは検知技術の本質であり、CIP-015が存在する大きな理由の一つでもあります。 この標準規格は、SolarWindsや同様の攻撃が、ESP エッジにおける従来のシグネチャベースの検知をすり抜けてしまったことを受けて策定されました。異常検知は、シグネチャに引っかかるのではなく、正当なツールや認証情報を悪用して「現地のリソースを活用して活動する(Living Off the Land)」攻撃者を捕捉するためのものです。
つまり、異常検知が必要なのか、それとも既知の攻撃を検知する侵入検知システムが必要なのかを知りたいのであれば、正直なところ、その両方だと言えます。これらは並行して稼働しており、何が起きているのかという全体像は、ほとんどの場合、この2つの組み合わせによって把握されるものです。
異常検知手法
CIP-015の技術的根拠では、4つの異常検知手法が挙げられています。これらは、1つだけを選ぶメニューというよりは、ツールボックスとして捉えるのが最適です:
- シグネチャベースの検知では、既知の悪意のあるトラフィック、シグネチャルール、その他のIOCなど、定義済みの異常を特定します。文字通り、ルールを記述することになります。
- 行動検知では、数学的手法を用いて統計的に有意な逸脱を抽出します。ここでいうベースラインは、静的(再生成されるまで固定)または動的(継続的に調整される)のいずれかです。リレーからRTACへのデータストリームが、通常は1メガビットで動作しているにもかかわらず、突然10メガビットに跳ね上がった場合、これは調査に値する統計的な異常ですが、悪意のある攻撃である可能性もあれば、単にファームウェアのアップグレードによるものかもしれない点に留意する必要があります。
- 設定チェックでは、設定ミスのあるデバイス、v3ではなくSNMPv1の使用、証明書なしのRDP、セキュリティ対策が不十分なリモートツールなど、望ましくない設定やセキュリティ上の問題を発見します。とはいえ、ここでも状況次第です。既知の脆弱性があるプロトコルであっても、それを安全に運用している施設においては、依然として適切な運用上の選択となり得るのです。
- ベースライン逸脱は、公益事業者がINSMのために導入している施策の多くの中核をなすものです。これには、新しい機器、新しい通信方式、新しいプロトコル、新しい機能コードなど、通常とは異なるあらゆるものが含まれます。
ベースラインからの逸脱を分析する上で最も重要なのは、「ベースライン」という言葉が深度によって異なる意味を持つためです。これを3つのレベルに分けて考えるのが最も実用的です:
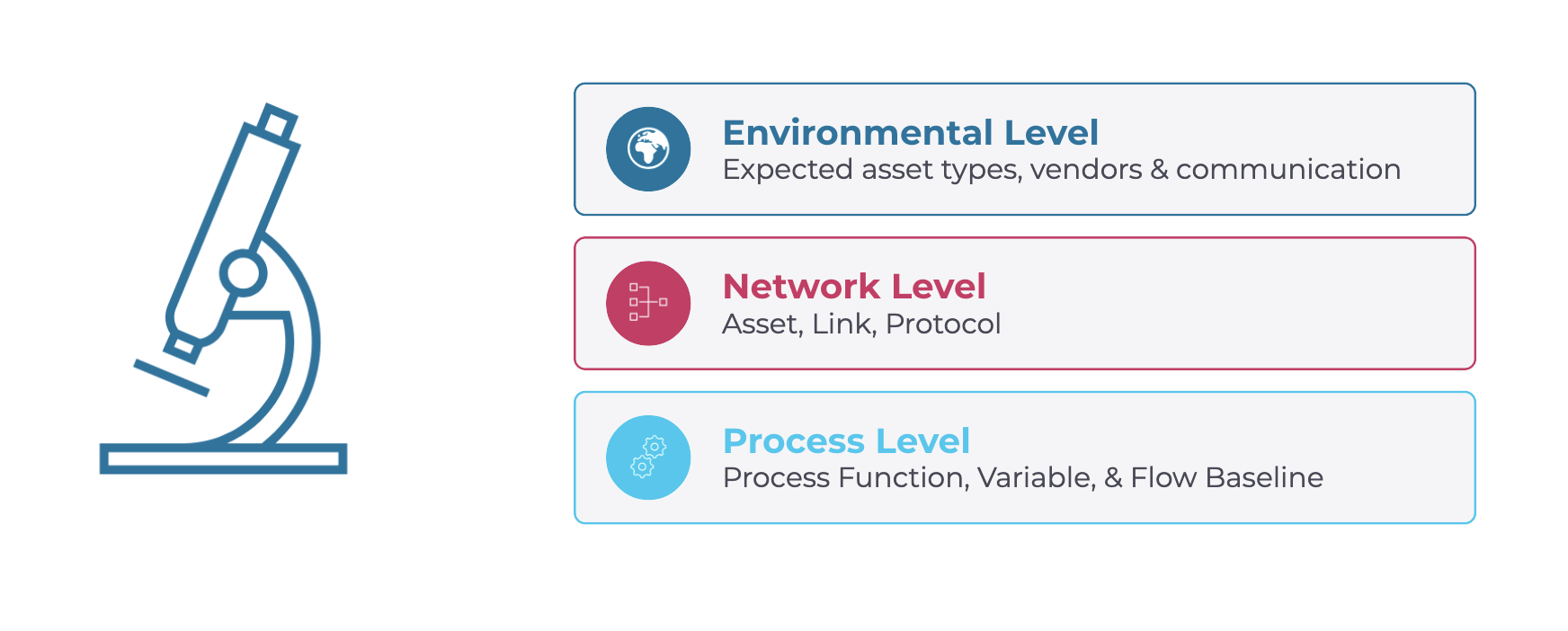
- 環境レベルとは、大まかな区分を指します。SELおよびDNP3を採用している環境であれば、SEL以外のデバイスや、DNP3を使用していない産業用プロトコルはすべて、基準からの逸脱となります。
- ネットワークレベルでは、特定のアセット、リンク、プロトコルに焦点を当てます。新しいデバイスの追加、MACアドレスやIPアドレスの変更、2つのアセット間の新しいリンクの確立、あるいはリンク上の2つのアセット間で新しいプロトコルが使用されることなどが、逸脱とみなされます。
- プロセスレベルは 、関数コード、変数、値、そしてフローに至るまで詳細に及ぶ 。このレベルでは、プロトコル内の値が重要となる。深く掘り下げれば掘り下げるほど、得られる価値と可視性は高まるが、同時にノイズやメンテナンスの負担も増えることになる。
異常検知戦略をチームや環境に合わせて調整する
異常の検出は物語の始まりであり、結論ではありません。だからこそ、R1 第1.3部では、評価と検出を組み合わせています。 ネットワーク上に新しいノートパソコンが検出されたからといって、工場を停止させるわけではありません。その異常を評価し、誰かに確認を依頼し、悪意のあるものでなければリスクを受け入れることもあります。検出された異常であっても、それが想定内であると判断されれば、想定される範囲の一部となります。これは多くの場合、チューニングプロセスの一部ですが、調査において有用であるものの、異常としてトリガーされる必要のないアラートを無効にしないよう注意する必要があります。
たとえば、一時的なサイバー資産が特定されている場合、それらをオフにするのではなく、接続された際にアラートを発し、自動的にミュート状態にしておくほうがよいかもしれません。というのも、調査の段階になった際、そうしたアラートは相関関係や背景情報を把握する上で極めて貴重な情報となるからです。
適切な戦略とは、最終的には自チームの能力に見合ったものでなければなりません。OT 強固なOT を持つ大規模なチームであれば、プロセスレベルの監視へと踏み込むことも可能です。一方、小規模なチームの場合は、実際にサポートできる範囲を超えて無理をするよりも、ネットワークレベルに焦点を当て、行動分析やシグネチャベースの手法を活用し、そこから段階的に体制を構築していく方が賢明です。チームの戦力を分散させすぎることは、戦略とは言えません。 「bangの左側」に留まることが重要です。つまり、ネットワーク、プロセス、環境のいずれか一つだけでなく、これら全体を俯瞰して把握する必要があるということです。
最終的な感想
ベストプラクティスは、要するに次の通りです。自社のプログラムにおいて「異常」とは何を指すのかを定義し、それをどのように評価するかを定め、その2つの決定に基づいて検知機能を構築することです。シグネチャだけではINSMの趣旨を満たすことはできませんが、必ずしもプロセスレベルの詳細まで掘り下げる必要もありません。これはリスクベースの判断であり、組織やチームの実情に応じて、自社のプログラム内でその妥当性を説明すればよいのです。
この投稿では、ウェビナーで取り上げられた内容のほんの一部にしか触れていません。ウェビナーシリーズに登録し、第5回のアーカイブ動画をご覧いただければ、検出手法の完全な解説やベースライン値に関する議論など、議論の全容をご確認いただけます。また、これらの内容がご自身の環境にどのように適用できるかについてご相談されたい場合は、お気軽にお問い合わせください。私たちは皆様をサポートいたします。





.webp)


